|
I am an Applied Scientist at Amazon. I completed my PhD from the Department of Computer Science at The University of Texas at Austin, where I worked with Prof. Raymond Mooney and Prof. Scott Niekum. Before joining the PhD program at UT Austin, I completed my Bachelors degree at Indian Institute of Technology, Delhi and my Masters degree at New York University's Courant Institute of Mathematical Sciences. I have interned at Google's speech team, NVIDIA's autonomous driving team, Microsoft Research's NLP team, and Amazon's Alexa team. In my free time, I like reading non-fiction, and writing on Quora. |

|
|
I am broadly interested in machine learning, and its applications to natural language processing and robotics. |

|
Prasoon Goyal, Raymond J. Mooney, Scott Niekum arXiv preprint, 2021 We propose a novel setting where an agent is given a demonstration for a task (the source task), and a natural language description of the differences between the demonstrated task and a related but different task (the target task). Our goal is to train an agent to complete the target task in a zero-shot setting, that is, without any demonstrations for the target task. To this end, we introduce Language-Aided Reward and Value Adaptation (LARVA) which, given a source demonstration and a linguistic description of how the target task differs, learns to output a reward / value function that accurately describes the target task. Our experiments show that on a diverse set of adaptations, our approach is able to complete more than 95% of target tasks when using template-based descriptions, and more than 70% when using free-form natural language. |

|
Prasoon Goyal, Scott Niekum, Raymond J. Mooney Conference on Robot Learning (CoRL), 2020 Reinforcement learning (RL), particularly in sparse reward settings, often requires prohibitively large numbers of interactions with the environment, thereby limiting its applicability to complex problems. To address this, several prior approaches have used natural language to guide the agent's exploration. However, these approaches typically operate on structured representations of the environment, and/or assume some structure in the natural language commands. In this work, we propose a model that directly maps pixels to rewards, given a free-form natural language description of the task, which can then be used for policy learning. Our experiments on the Meta-World robot manipulation domain show that language-based rewards significantly improves the sample efficiency of policy learning, both in sparse and dense reward settings. |
|
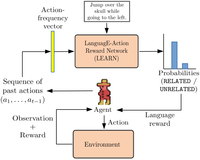
Prasoon Goyal, Scott Niekum, Raymond J. Mooney International Joint Conference on Artificial Intelligence (IJCAI), 2019 [Code + Data] Recent reinforcement learning (RL) approaches have shown strong performance in complex domains such as Atari games, but are often highly sample inefficient. A common approach to reduce interaction time with the environment is to use reward shaping, but designing appropriate shaping rewards is known to be difficult as well as time-consuming. In this work, we address this problem by using natural language instructions to perform reward shaping. We propose the LanguagE-Action Reward Network (LEARN), a framework that maps free-form natural language instructions to intermediate rewards based on actions taken by the agent. These intermediate language-based rewards can seamlessly be integrated into any standard reinforcement learning algorithm. Our experiments on Montezuma's Revenge demonstrate that for the same number of interactions with the environment, language-based rewards lead to successful completion of the task significantly more often, compared to learning without language. |
|
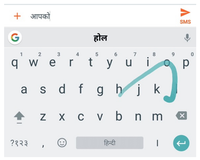
Lars Hellsten, Brian Roark, Prasoon Goyal, Cyril Allauzen, Françoise Beaufays, Tom Ouyang, Michael Riley, David Rybach International Conference on Finite State Methods and Natural Language Processing (FSMNLP), 2017 We present an extension to a mobile keyboard input decoder based on finite-state transducers that provides general transliteration support, and demonstrate its use for input of South Asian languages using a QWERTY keyboard. On-device keyboard decoders must operate under strict latency and memory constraints, and we present several transducer optimizations that allow for high accuracy decoding under such constraints. Our methods yield substantial accuracy improvements and latency reductions over an existing baseline transliteration keyboard approach. The resulting system was launched for 22 languages in Google Gboard in the first half of 2017. |
|
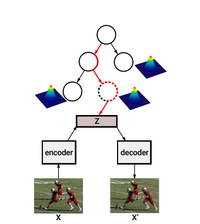
Prasoon Goyal, Zhiting Hu, Xiaodan Liang, Chenyu Wang, Eric Xing International Conference on Computer Vision (ICCV), 2017 Most work on VAEs use a rather simple prior over the latent variables such as standard normal distribution, thereby restricting its applications to relatively simple phenomena. In this work, we propose hierarchical nonparametric variational autoencoders, which combines tree-structured Bayesian nonparametric priors with VAEs, to enable infinite flexibility of the latent representation space. Both the neural parameters and Bayesian priors are learned jointly using tailored variational inference. The resulting model induces a hierarchical structure of latent semantic concepts underlying the data corpus, and infers accurate representations of data instances. |

|
We trained a convolutional neural network (CNN) to map raw pixels from a single front-facing camera directly to steering commands. This end-to-end approach proved surprisingly powerful. With minimum training data from humans the system learns to drive in traffic on local roads with or without lane markings and on highways. It also operates in areas with unclear visual guidance such as in parking lots and on unpaved roads. |
|
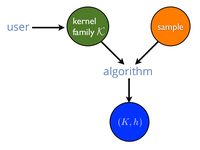
We present a new framework for learning a predictor in the presence of multiple kernel functions where the learner selects or extracts several kernel functions from potentially complex families and finds an accurate predictor defined in terms of these functions. We show that our algorithm benefits from strong learning guarantees suggesting a new regularization penalty depending on the Rademacher complexities of the families of kernel functions used. Our algorithm admits several other favorable properties: its optimization problem is convex, it allows for learning with non-PDS kernels, and the solutions are highly sparse, resulting in improved classification speed and memory requirements. |
|
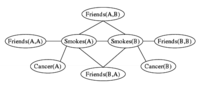
Lifted inference algorithms for probabilistic first-order logic frameworks such as Markov logic networks (MLNs) identify symmetries in the first-order representation and reduce the inference problem over a large probabilistic model to an inference problem over a much smaller model. In this paper, we present two new lifting rules, which enable fast MAP inference in a large class of MLNs. We prove that our two new rules are sound and demonstrate via a detailed experimental evaluation that our approach is superior in terms of scalability and MAP solution quality to the state of the art approaches. |
|
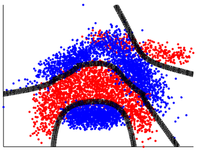
We generalize Localized Multiple Kernel Learning so as to learn a tree-based primal feature embedding which is high dimensional and sparse. We develop routines for optimizing over the space of tree-structured features and efficiently scale to problems with more than half a million training points. Experiments on benchmark data sets reveal that our formulation can reduce prediction costs by more than three orders of magnitude in some cases with a moderate sacrifice in classification accuracy as compared to RBF-SVMs. |
|
Template borrowed from here. |